Abstract
In this paper, we present InstruNET, a convolutional neural network (CNN) designed for multi-label instrument classification. Originally, our objective was to develop an end- to-end pipeline that could take a raw, mixed audio track and generate sheet music for each individual instrument. To address this separation task, we experimented with Non- Negative Matrix Factorization (NMF) and a custom Spectrogram U-Net to reconstruct individual spectrograms from the mixed .wav file. However, due to limitations such as poor signal reconstruction, high model complexity, and constrained computational resources, we redefined our project scope to focus on the more foundational problem of detecting instrument presence within mixed audio files.
Under this new scope, we curated a high- quality dataset from the BabySlakh dataset by extracting metadata, isolating stems, and organizing them into folders grouped by instrument class. InstruNET was then trained on Mel spectrograms of this refined dataset to perform multi-label classification across 14 classes. Our model significantly outperformed different approaches, including YAMNet (72.1%) and a shallow feed-forward network (58.9%), achieving an accuracy of 82.1%. These results show the effectiveness of convolutional architectures for instrument identification in mixed-instrument music files and lay the groundwork for future work in source separation and transcription
Motivation
The motivation behind InstruNET is the lack of an efficient pipeline that can generate individual sheet music for multiple instruments directly from mixed raw audio. While several systems can generate sheet music from isolated instrument tracks, few can handle the challenge of instrument identification and separation from unprocessed music. InstruNET aims to bridge this gap, starting with a focus on multi-label instrument classification from mixed audio, laying the groundwork for future separation and transcription tasks.
Dataset Preparation
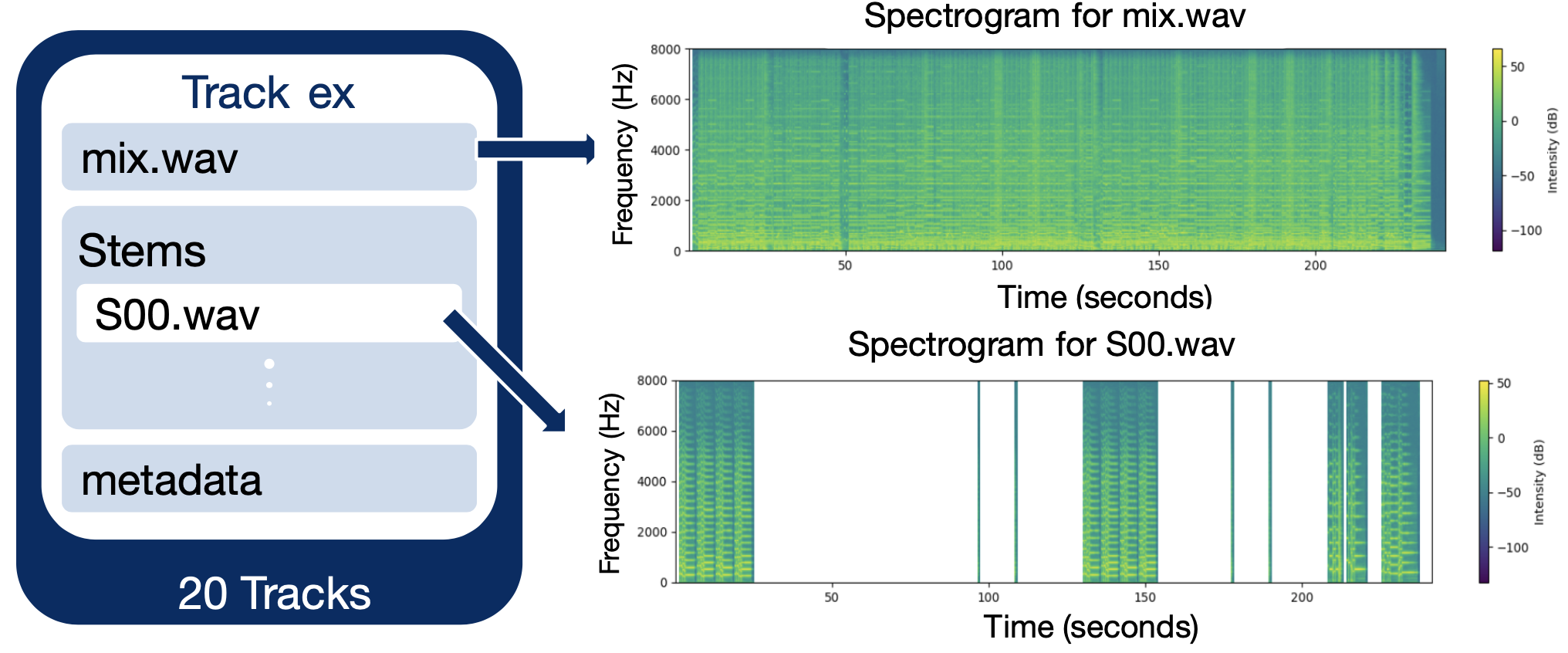
Using the BabySlakh dataset, we restructured metadata and audio files to group stems by instrument class. We focused on five dominant instruments—guitar, strings, piano, bass, and drums—and excluded rare or sparse classes to improve class balance. Each audio input was then converted to a spectrogram for training, enabling the model to learn from both time and frequency domain patterns.
Model Architecture
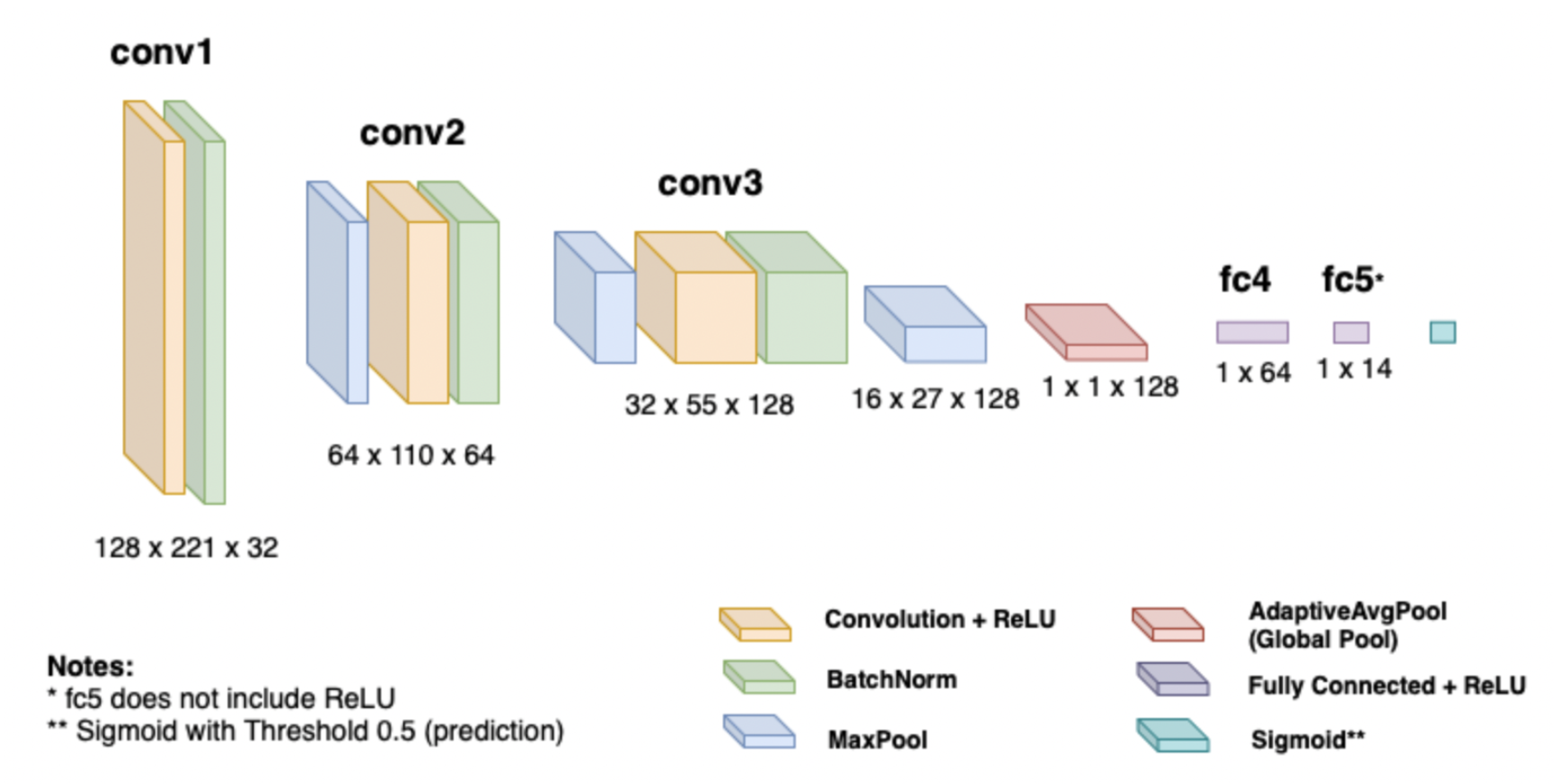
InstruNET uses a convolutional neural network with three convolutional layers (32, 64, 128 channels), followed by batch normalization, ReLU activations, and max pooling. The final layers include adaptive average pooling and two fully connected layers with dropout. This structure allows the model to capture hierarchical patterns in spectrograms, culminating in multi-label predictions across 14 instrument classes using binary cross-entropy loss and a sigmoid activation.
Results
The InstruNET model was evaluated against two baselines: a shallow feedforward neural network (Baseline) and a pre-trained audio classification model (YAMNet). As shown in Table 2, InstruNET achieved the highest scores across all weighted evaluation metrics—accuracy, F1-score, precision, and recall—highlighting its superior performance in multi-label instrument classification.
| Metric | Baseline | YAMNet | InstruNET |
|---|---|---|---|
| Accuracy | 58.9% | 72.1% | 82.1% |
| F1-score | 0.772 | 0.776 | 0.832 |
| Precision | 0.779 | 0.738 | 0.848 |
| Recall | 0.773 | 0.731 | 0.839 |
Next Steps
Ultimately, the project resulted in a model capable of identifying the instruments in a mixed audio track. As a result, the next step involves performing source separation to isolate each identified instrument into distinct audio files. A promising approach involves using a model similar to Demucs, a state-of-the-art source separation architecture developed by Facebook AI Research. Demucs employs an encoder-decoder structure with bidirectional LSTM layers to reconstruct high-resolution waveforms, and could be extended to include additional instrument classes from the Slakh dataset.
After obtaining separated stems, each instrument's audio can be transcribed into MIDI format using Basic Pitch, an open-source transcription tool developed by Spotify. Basic Pitch uses neural networks to convert audio to MIDI representations. These MIDI files can then be imported into conventional notation software such as MuseScore to generate standardized sheet music.
This proposed three-stage pipeline—instrument identification, source separation, and transcription—offers a promising direction for future development. It will enable raw mixed-instrument recordings to be transformed into individual written scores, contributing to the accessibility of music education and streamlining music production workflows.